Benchmark BiGRU - 2020 April 01¶
[1]:
import datetime
import numpy as np
from matplotlib import pyplot as plt
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, random_split
from tqdm import tqdm
import seaborn as sns
from tst.loss import OZELoss
from src.benchmark import BiGRU
from src.dataset import OzeDataset
from src.utils import compute_loss
from src.visualization import map_plot_function, plot_values_distribution, plot_error_distribution, plot_errors_threshold, plot_visual_sample
[2]:
# Training parameters
DATASET_PATH = 'datasets/dataset_CAPT_v7.npz'
BATCH_SIZE = 8
NUM_WORKERS = 4
LR = 1e-4
EPOCHS = 30
# Model parameters
d_model = 48 # Lattent dim
N = 4 # Number of layers
dropout = 0.2 # Dropout rate
d_input = 38 # From dataset
d_output = 8 # From dataset
# Config
sns.set()
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(f"Using device {device}")
Using device cuda:0
Training¶
Load dataset¶
[3]:
ozeDataset = OzeDataset(DATASET_PATH)
dataset_train, dataset_val, dataset_test = random_split(ozeDataset, (38000, 1000, 1000))
[4]:
dataloader_train = DataLoader(dataset_train,
batch_size=BATCH_SIZE,
shuffle=True,
num_workers=NUM_WORKERS,
pin_memory=False
)
dataloader_val = DataLoader(dataset_val,
batch_size=BATCH_SIZE,
shuffle=True,
num_workers=NUM_WORKERS
)
dataloader_test = DataLoader(dataset_test,
batch_size=BATCH_SIZE,
shuffle=False,
num_workers=NUM_WORKERS
)
Load network¶
[5]:
# Load transformer with Adam optimizer and MSE loss function
net = BiGRU(d_input, d_model, d_output, N, dropout=dropout, bidirectional=True).to(device)
optimizer = optim.Adam(net.parameters(), lr=LR)
loss_function = OZELoss(alpha=0.3)
Train¶
[6]:
model_save_path = f'models/model_LSTM_{datetime.datetime.now().strftime("%Y_%m_%d__%H%M%S")}.pth'
val_loss_best = np.inf
# Prepare loss history
hist_loss = np.zeros(EPOCHS)
hist_loss_val = np.zeros(EPOCHS)
for idx_epoch in range(EPOCHS):
running_loss = 0
with tqdm(total=len(dataloader_train.dataset), desc=f"[Epoch {idx_epoch+1:3d}/{EPOCHS}]") as pbar:
for idx_batch, (x, y) in enumerate(dataloader_train):
optimizer.zero_grad()
# Propagate input
netout = net(x.to(device))
# Comupte loss
loss = loss_function(y.to(device), netout)
# Backpropage loss
loss.backward()
# Update weights
optimizer.step()
running_loss += loss.item()
pbar.set_postfix({'loss': running_loss/(idx_batch+1)})
pbar.update(x.shape[0])
train_loss = running_loss/len(dataloader_train)
val_loss = compute_loss(net, dataloader_val, loss_function, device).item()
pbar.set_postfix({'loss': train_loss, 'val_loss': val_loss})
hist_loss[idx_epoch] = train_loss
hist_loss_val[idx_epoch] = val_loss
if val_loss < val_loss_best:
val_loss_best = val_loss
torch.save(net.state_dict(), model_save_path)
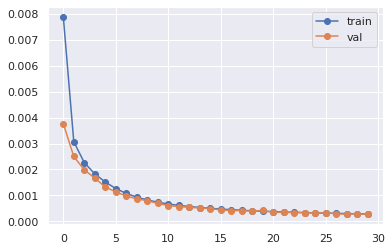
plt.plot(hist_loss, 'o-', label='train')
plt.plot(hist_loss_val, 'o-', label='val')
plt.legend()
print(f"model exported to {model_save_path} with loss {val_loss_best:5f}")
[Epoch 1/30]: 100%|██████████| 38000/38000 [17:11<00:00, 36.84it/s, loss=0.00789, val_loss=0.00377]
[Epoch 2/30]: 100%|██████████| 38000/38000 [17:09<00:00, 36.90it/s, loss=0.00307, val_loss=0.0025]
[Epoch 3/30]: 100%|██████████| 38000/38000 [17:14<00:00, 36.73it/s, loss=0.00227, val_loss=0.00198]
[Epoch 4/30]: 100%|██████████| 38000/38000 [17:13<00:00, 36.78it/s, loss=0.00183, val_loss=0.00167]
[Epoch 5/30]: 100%|██████████| 38000/38000 [17:03<00:00, 37.12it/s, loss=0.00152, val_loss=0.00132]
[Epoch 6/30]: 100%|██████████| 38000/38000 [17:01<00:00, 37.19it/s, loss=0.00126, val_loss=0.00114]
[Epoch 7/30]: 100%|██████████| 38000/38000 [17:06<00:00, 37.00it/s, loss=0.00108, val_loss=0.000976]
[Epoch 8/30]: 100%|██████████| 38000/38000 [17:18<00:00, 36.58it/s, loss=0.000932, val_loss=0.00087]
[Epoch 9/30]: 100%|██████████| 38000/38000 [17:16<00:00, 36.65it/s, loss=0.000825, val_loss=0.000795]
[Epoch 10/30]: 100%|██████████| 38000/38000 [17:11<00:00, 36.84it/s, loss=0.000739, val_loss=0.000694]
[Epoch 11/30]: 100%|██████████| 38000/38000 [17:12<00:00, 36.80it/s, loss=0.00067, val_loss=0.000609]
[Epoch 12/30]: 100%|██████████| 38000/38000 [17:24<00:00, 36.39it/s, loss=0.000616, val_loss=0.000569]
[Epoch 13/30]: 100%|██████████| 38000/38000 [17:16<00:00, 36.67it/s, loss=0.000572, val_loss=0.000543]
[Epoch 14/30]: 100%|██████████| 38000/38000 [17:10<00:00, 36.89it/s, loss=0.000534, val_loss=0.000515]
[Epoch 15/30]: 100%|██████████| 38000/38000 [17:12<00:00, 36.81it/s, loss=0.000503, val_loss=0.00049]
[Epoch 16/30]: 100%|██████████| 38000/38000 [17:15<00:00, 36.71it/s, loss=0.000474, val_loss=0.000442]
[Epoch 17/30]: 100%|██████████| 38000/38000 [17:13<00:00, 36.77it/s, loss=0.000451, val_loss=0.000419]
[Epoch 18/30]: 100%|██████████| 38000/38000 [17:06<00:00, 37.03it/s, loss=0.000428, val_loss=0.00041]
[Epoch 19/30]: 100%|██████████| 38000/38000 [17:09<00:00, 36.93it/s, loss=0.000408, val_loss=0.0004]
[Epoch 20/30]: 100%|██████████| 38000/38000 [17:09<00:00, 36.90it/s, loss=0.00039, val_loss=0.00042]
[Epoch 21/30]: 100%|██████████| 38000/38000 [17:08<00:00, 36.93it/s, loss=0.000375, val_loss=0.000351]
[Epoch 22/30]: 100%|██████████| 38000/38000 [17:10<00:00, 36.86it/s, loss=0.000361, val_loss=0.000343]
[Epoch 23/30]: 100%|██████████| 38000/38000 [17:15<00:00, 36.71it/s, loss=0.000348, val_loss=0.000341]
[Epoch 24/30]: 100%|██████████| 38000/38000 [17:14<00:00, 36.73it/s, loss=0.000337, val_loss=0.000338]
[Epoch 25/30]: 100%|██████████| 38000/38000 [17:01<00:00, 37.19it/s, loss=0.000329, val_loss=0.000318]
[Epoch 26/30]: 100%|██████████| 38000/38000 [17:11<00:00, 36.84it/s, loss=0.000317, val_loss=0.000333]
[Epoch 27/30]: 100%|██████████| 38000/38000 [17:13<00:00, 36.78it/s, loss=0.000308, val_loss=0.00029]
[Epoch 28/30]: 100%|██████████| 38000/38000 [17:01<00:00, 37.22it/s, loss=0.000303, val_loss=0.00028]
[Epoch 29/30]: 100%|██████████| 38000/38000 [17:07<00:00, 37.00it/s, loss=0.000291, val_loss=0.000292]
[Epoch 30/30]: 100%|██████████| 38000/38000 [17:14<00:00, 36.73it/s, loss=0.000283, val_loss=0.000268]
model exported to models/model_LSTM_2020_04_01__102333.pth with loss 0.000268
Validation¶
[7]:
_ = net.eval()
Evaluate on the test dataset¶
[8]:
predictions = np.empty(shape=(len(dataloader_test.dataset), 168, 8))
idx_prediction = 0
with torch.no_grad():
for x, y in tqdm(dataloader_test, total=len(dataloader_test)):
netout = net(x.to(device)).cpu().numpy()
predictions[idx_prediction:idx_prediction+x.shape[0]] = netout
idx_prediction += x.shape[0]
100%|██████████| 125/125 [00:05<00:00, 20.85it/s]
Plot results on a sample¶
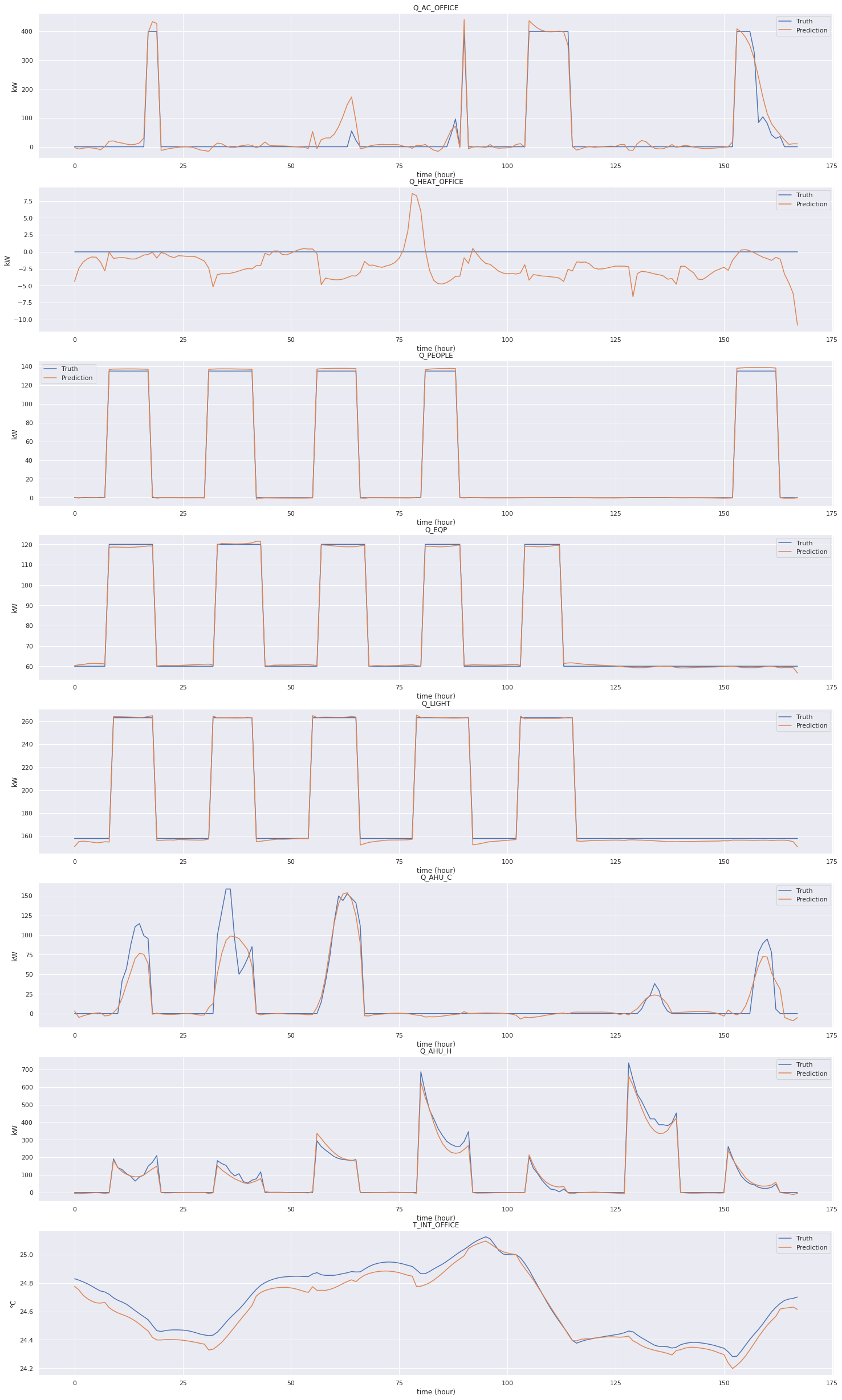
[9]:
map_plot_function(ozeDataset, predictions, plot_visual_sample, dataset_indices=dataloader_test.dataset.indices)
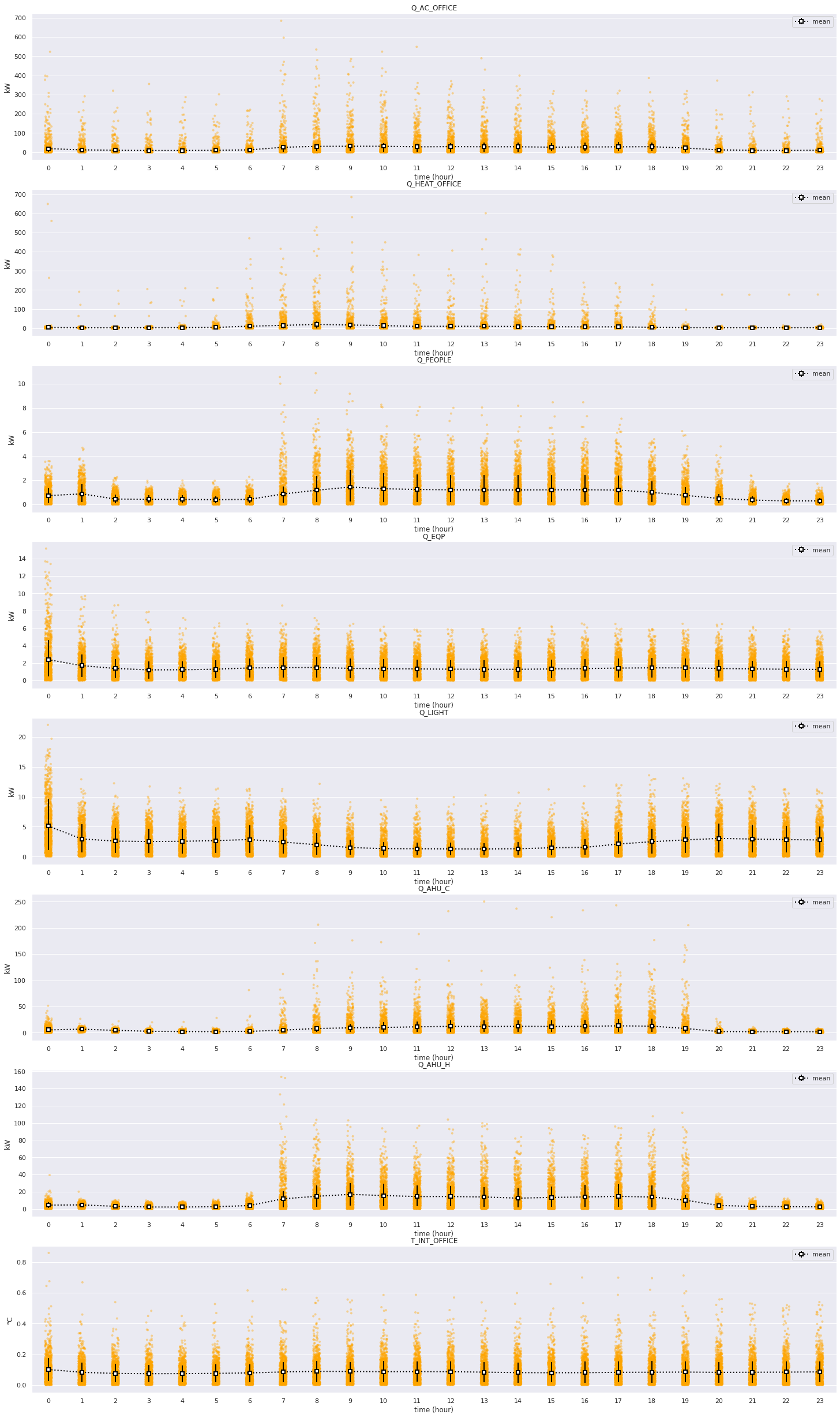
Plot error distributions¶
[10]:
map_plot_function(ozeDataset, predictions, plot_error_distribution, dataset_indices=dataloader_test.dataset.indices, time_limit=24)
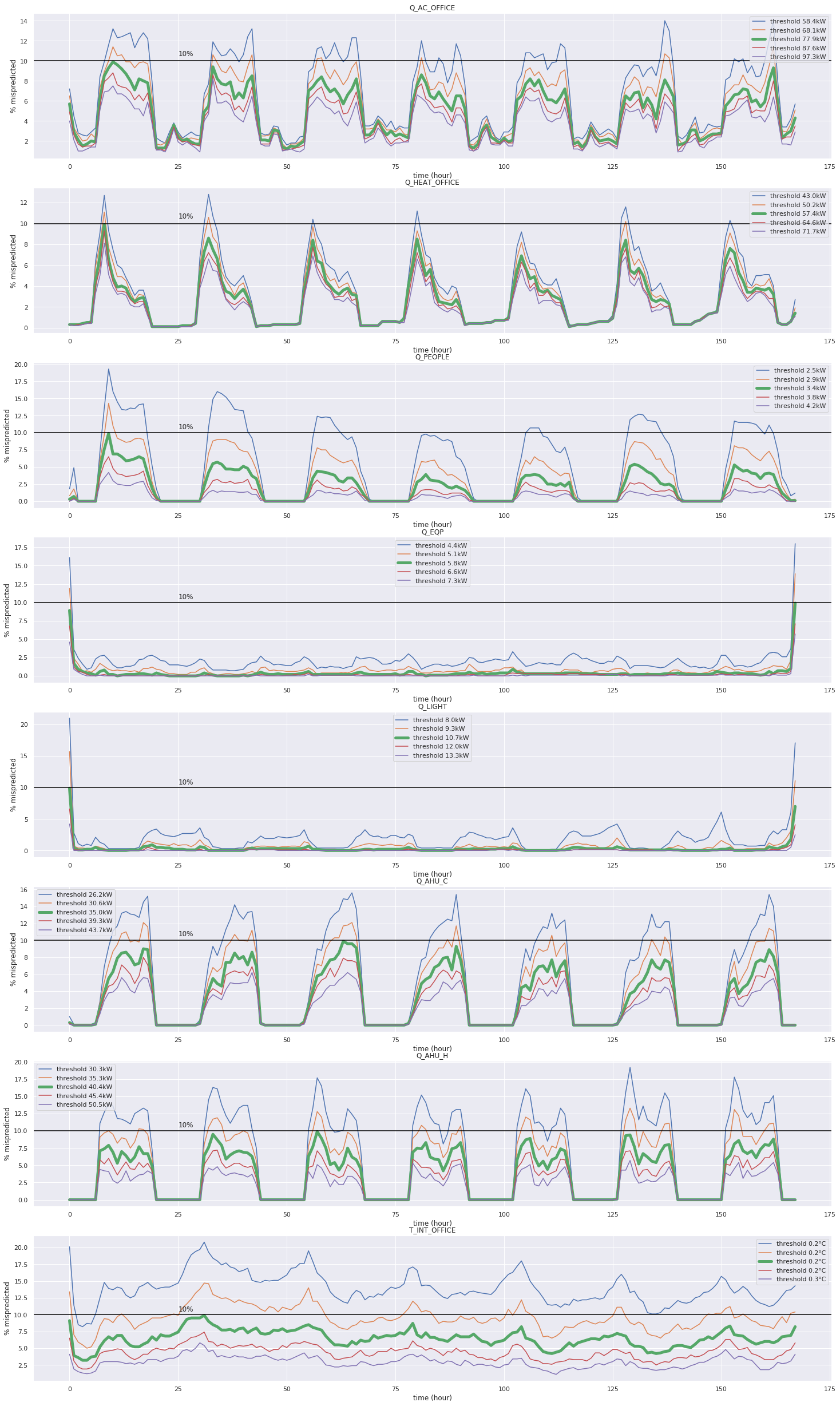
Plot mispredictions thresholds¶
[11]:
map_plot_function(ozeDataset, predictions, plot_errors_threshold, plot_kwargs={'error_band': 0.1}, dataset_indices=dataloader_test.dataset.indices)