Classic - 2020 March 12¶
[1]:
import datetime
import numpy as np
from matplotlib import pyplot as plt
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, random_split
from tqdm import tqdm
import seaborn as sns
from tst import Transformer
from tst.loss import OZELoss
from src.dataset import OzeDataset
from src.utils import visual_sample, compute_loss
[2]:
# Training parameters
DATASET_PATH = 'datasets/dataset_CAPT_v7.npz'
BATCH_SIZE = 8
NUM_WORKERS = 4
LR = 2e-4
EPOCHS = 30
# Model parameters
d_model = 48 # Lattent dim
q = 8 # Query size
v = 8 # Value size
h = 4 # Number of heads
N = 4 # Number of encoder and decoder to stack
attention_size = 24 # Attention window size
dropout = 0.2 # Dropout rate
pe = None # Positional encoding
chunk_mode = None
d_input = 38 # From dataset
d_output = 8 # From dataset
# Config
sns.set()
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(f"Using device {device}")
Using device cpu
Training¶
Load dataset¶
[3]:
ozeDataset = OzeDataset(DATASET_PATH)
dataset_train, dataset_val, dataset_test = random_split(ozeDataset, (38000, 1000, 1000))
dataloader_train = DataLoader(dataset_train,
batch_size=BATCH_SIZE,
shuffle=True,
num_workers=NUM_WORKERS,
pin_memory=False
)
dataloader_val = DataLoader(dataset_val,
batch_size=BATCH_SIZE,
shuffle=True,
num_workers=NUM_WORKERS
)
dataloader_test = DataLoader(dataset_test,
batch_size=BATCH_SIZE,
shuffle=False,
num_workers=NUM_WORKERS
)
Load network¶
[4]:
# Load transformer with Adam optimizer and MSE loss function
net = Transformer(d_input, d_model, d_output, q, v, h, N, attention_size=attention_size, dropout=dropout, chunk_mode=chunk_mode, pe=pe).to(device)
optimizer = optim.Adam(net.parameters(), lr=LR)
loss_function = OZELoss(alpha=0.3)
Train¶
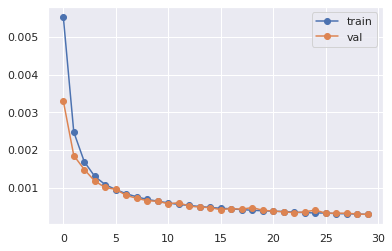
[5]:
model_save_path = f'models/model_{datetime.datetime.now().strftime("%Y_%m_%d__%H%M%S")}.pth'
val_loss_best = np.inf
# Prepare loss history
hist_loss = np.zeros(EPOCHS)
hist_loss_val = np.zeros(EPOCHS)
for idx_epoch in range(EPOCHS):
running_loss = 0
with tqdm(total=len(dataloader_train.dataset), desc=f"[Epoch {idx_epoch+1:3d}/{EPOCHS}]") as pbar:
for idx_batch, (x, y) in enumerate(dataloader_train):
optimizer.zero_grad()
# Propagate input
netout = net(x.to(device))
# Comupte loss
loss = loss_function(y.to(device), netout)
# Backpropage loss
loss.backward()
# Update weights
optimizer.step()
running_loss += loss.item()
pbar.set_postfix({'loss': running_loss/(idx_batch+1)})
pbar.update(x.shape[0])
train_loss = running_loss/len(dataloader_train)
val_loss = compute_loss(net, dataloader_val, loss_function, device).item()
pbar.set_postfix({'loss': train_loss, 'val_loss': val_loss})
hist_loss[idx_epoch] = train_loss
hist_loss_val[idx_epoch] = val_loss
if val_loss < val_loss_best:
val_loss_best = val_loss
torch.save(net.state_dict(), model_save_path)
plt.plot(hist_loss, 'o-', label='train')
plt.plot(hist_loss_val, 'o-', label='val')
plt.legend()
print(f"model exported to {model_save_path} with loss {val_loss_best:5f}")
[Epoch 1/30]: 100%|██████████| 38000/38000 [26:53<00:00, 23.55it/s, loss=0.00554, val_loss=0.0033]
[Epoch 2/30]: 100%|██████████| 38000/38000 [26:33<00:00, 23.85it/s, loss=0.00247, val_loss=0.00185]
[Epoch 3/30]: 100%|██████████| 38000/38000 [26:59<00:00, 23.46it/s, loss=0.00169, val_loss=0.00148]
[Epoch 4/30]: 100%|██████████| 38000/38000 [26:54<00:00, 23.54it/s, loss=0.00129, val_loss=0.00117]
[Epoch 5/30]: 100%|██████████| 38000/38000 [26:57<00:00, 23.49it/s, loss=0.00108, val_loss=0.001]
[Epoch 6/30]: 100%|██████████| 38000/38000 [26:59<00:00, 23.47it/s, loss=0.000946, val_loss=0.000952]
[Epoch 7/30]: 100%|██████████| 38000/38000 [26:57<00:00, 23.49it/s, loss=0.000834, val_loss=0.000791]
[Epoch 8/30]: 100%|██████████| 38000/38000 [26:49<00:00, 23.61it/s, loss=0.000753, val_loss=0.000714]
[Epoch 9/30]: 100%|██████████| 38000/38000 [27:00<00:00, 23.45it/s, loss=0.000683, val_loss=0.00065]
[Epoch 10/30]: 100%|██████████| 38000/38000 [26:54<00:00, 23.54it/s, loss=0.000637, val_loss=0.000634]
[Epoch 11/30]: 100%|██████████| 38000/38000 [26:58<00:00, 23.48it/s, loss=0.000591, val_loss=0.000569]
[Epoch 12/30]: 100%|██████████| 38000/38000 [27:00<00:00, 23.45it/s, loss=0.000549, val_loss=0.000596]
[Epoch 13/30]: 100%|██████████| 38000/38000 [27:09<00:00, 23.32it/s, loss=0.000524, val_loss=0.000506]
[Epoch 14/30]: 100%|██████████| 38000/38000 [26:53<00:00, 23.55it/s, loss=0.000496, val_loss=0.00048]
[Epoch 15/30]: 100%|██████████| 38000/38000 [27:06<00:00, 23.37it/s, loss=0.00047, val_loss=0.000466]
[Epoch 16/30]: 100%|██████████| 38000/38000 [27:09<00:00, 23.32it/s, loss=0.000448, val_loss=0.000412]
[Epoch 17/30]: 100%|██████████| 38000/38000 [27:13<00:00, 23.26it/s, loss=0.000436, val_loss=0.000442]
[Epoch 18/30]: 100%|██████████| 38000/38000 [27:04<00:00, 23.40it/s, loss=0.000412, val_loss=0.000424]
[Epoch 19/30]: 100%|██████████| 38000/38000 [27:10<00:00, 23.31it/s, loss=0.000397, val_loss=0.000468]
[Epoch 20/30]: 100%|██████████| 38000/38000 [27:15<00:00, 23.24it/s, loss=0.000381, val_loss=0.000396]
[Epoch 21/30]: 100%|██████████| 38000/38000 [27:16<00:00, 23.22it/s, loss=0.000372, val_loss=0.000375]
[Epoch 22/30]: 100%|██████████| 38000/38000 [27:16<00:00, 23.23it/s, loss=0.000361, val_loss=0.000355]
[Epoch 23/30]: 100%|██████████| 38000/38000 [27:08<00:00, 23.34it/s, loss=0.000346, val_loss=0.000331]
[Epoch 24/30]: 100%|██████████| 38000/38000 [27:12<00:00, 23.27it/s, loss=0.000334, val_loss=0.000352]
[Epoch 25/30]: 100%|██████████| 38000/38000 [27:14<00:00, 23.24it/s, loss=0.000324, val_loss=0.000401]
[Epoch 26/30]: 100%|██████████| 38000/38000 [27:18<00:00, 23.19it/s, loss=0.000324, val_loss=0.000319]
[Epoch 27/30]: 100%|██████████| 38000/38000 [27:19<00:00, 23.18it/s, loss=0.000305, val_loss=0.000319]
[Epoch 28/30]: 100%|██████████| 38000/38000 [27:12<00:00, 23.28it/s, loss=0.000303, val_loss=0.000318]
[Epoch 29/30]: 100%|██████████| 38000/38000 [27:19<00:00, 23.18it/s, loss=0.000295, val_loss=0.000297]
[Epoch 30/30]: 100%|██████████| 38000/38000 [27:15<00:00, 23.23it/s, loss=0.000287, val_loss=0.000286]
model exported to models/model_2020_03_10__231146.pth with loss 0.000286
Validation¶
[6]:
_ = net.eval()
Plot results on a sample¶
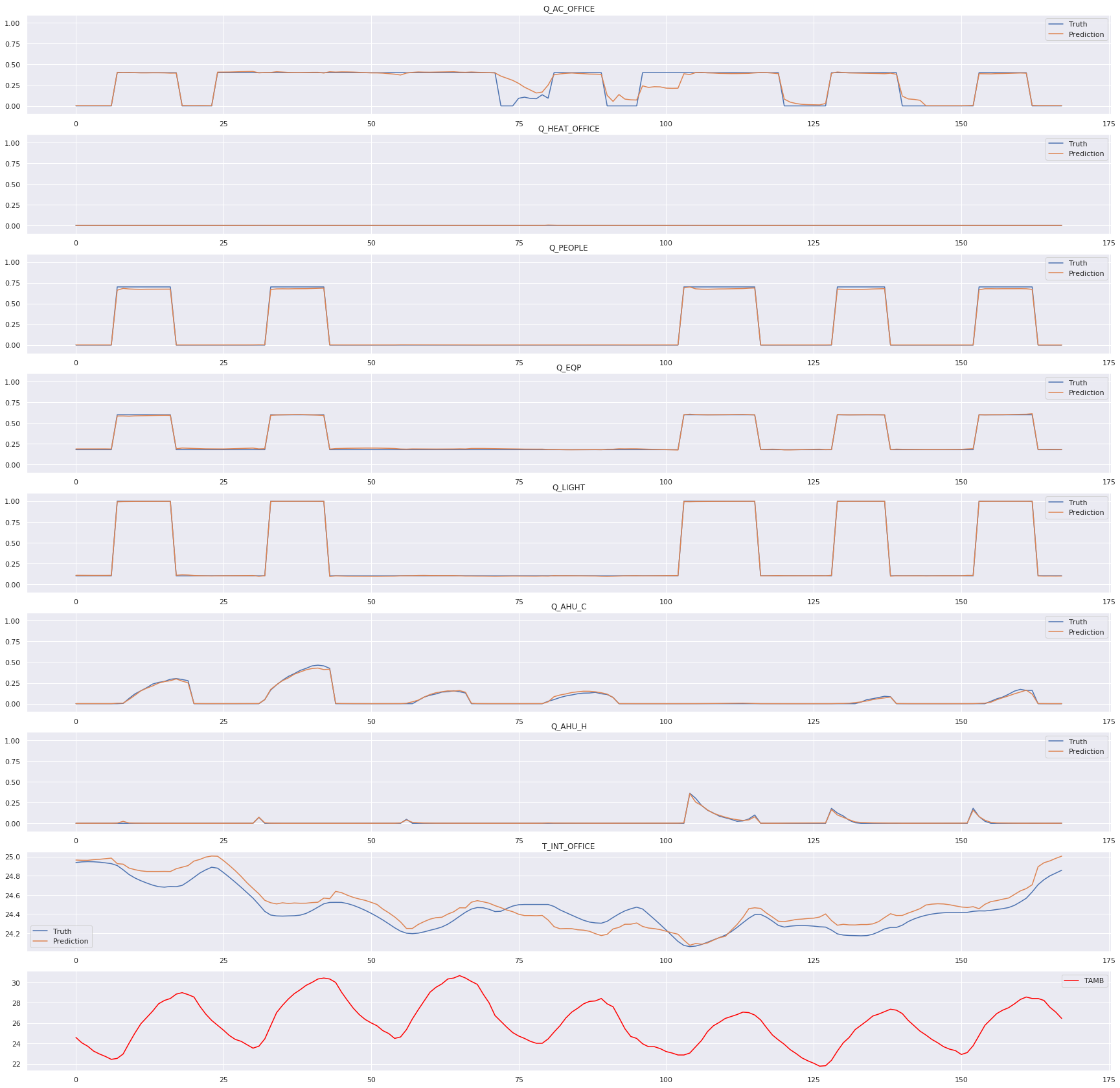
[7]:
visual_sample(dataloader_test, net, device)
plt.savefig("fig")
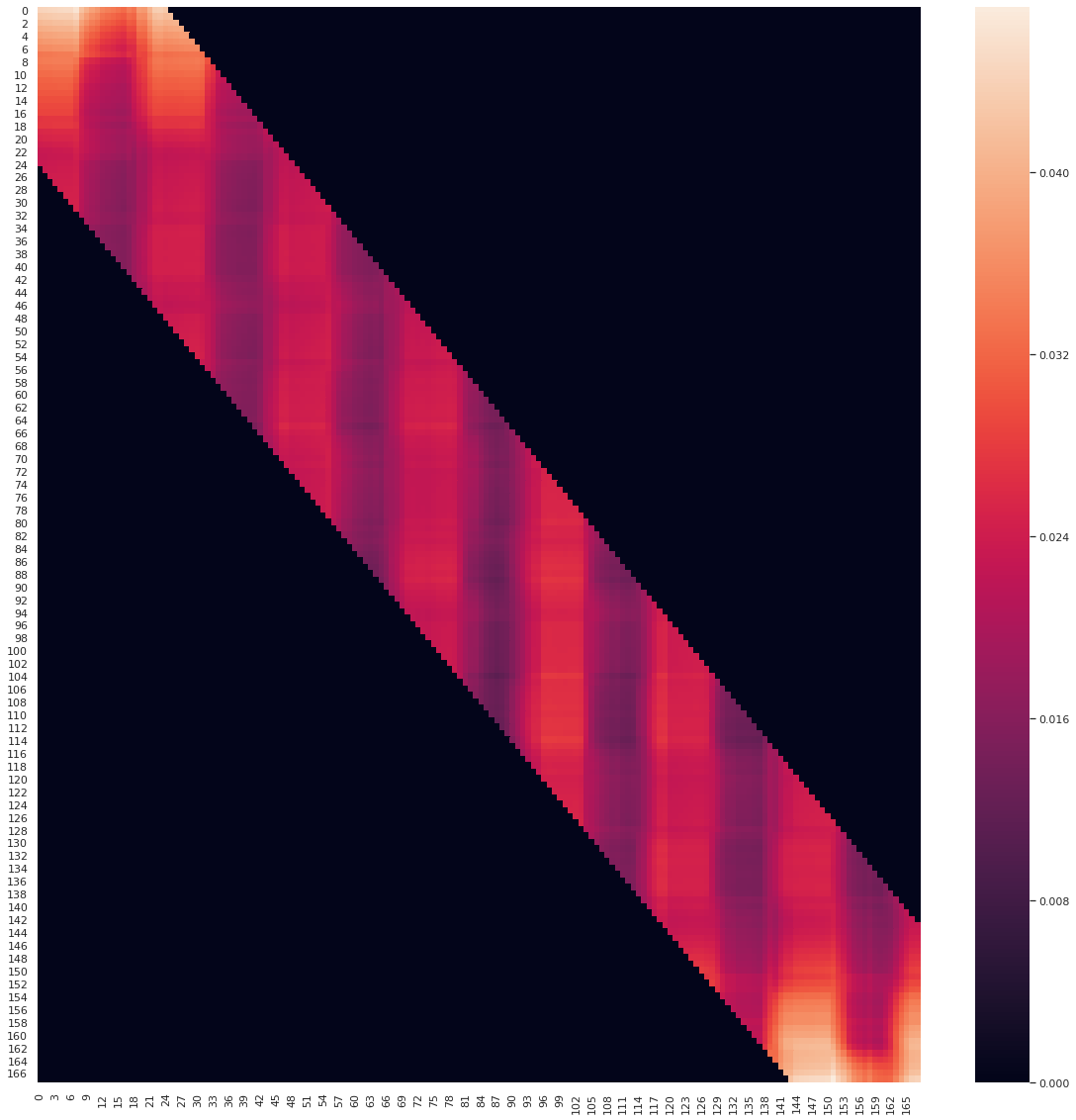
Plot encoding attention map¶
[8]:
# Select first encoding layer
encoder = net.layers_encoding[0]
# Get the first attention map
attn_map = encoder.attention_map[0].cpu()
# Plot
plt.figure(figsize=(20, 20))
sns.heatmap(attn_map)
plt.savefig("attention_map")
Evaluate on the test dataset¶
[9]:
predictions = np.empty(shape=(len(dataloader_test.dataset), 168, 8))
idx_prediction = 0
with torch.no_grad():
for x, y in tqdm(dataloader_test, total=len(dataloader_test)):
netout = net(x.to(device)).cpu().numpy()
predictions[idx_prediction:idx_prediction+x.shape[0]] = netout
idx_prediction += x.shape[0]
100%|██████████| 125/125 [00:17<00:00, 7.00it/s]
[10]:
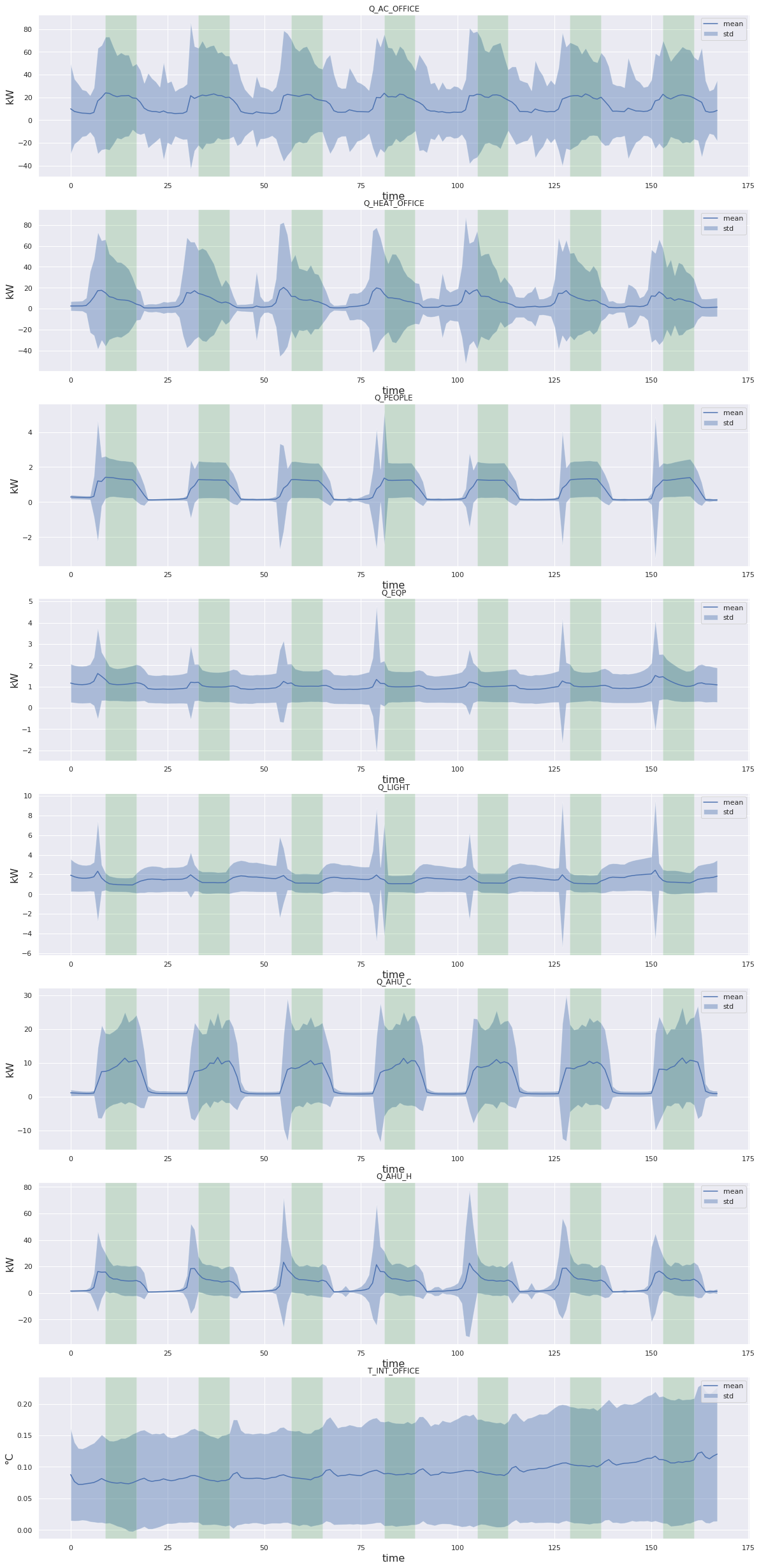
fig, axes = plt.subplots(8, 1)
fig.set_figwidth(20)
fig.set_figheight(40)
plt.subplots_adjust(bottom=0.05)
occupancy = (dataloader_test.dataset.dataset._x.numpy()[..., dataloader_test.dataset.dataset.labels["Z"].index("occupancy")].mean(axis=0)>0.5).astype(float)
y_true_full = dataloader_test.dataset.dataset._y[dataloader_test.dataset.indices].numpy()
for idx_label, (label, ax) in enumerate(zip(dataloader_test.dataset.dataset.labels['X'], axes)):
# Select output to plot
y_true = y_true_full[..., idx_label]
y_pred = predictions[..., idx_label]
# Rescale
y_true = dataloader_test.dataset.dataset.rescale(y_true, idx_label)
y_pred = dataloader_test.dataset.dataset.rescale(y_pred, idx_label)
if label.startswith('Q_'):
# Convert kJ/h to kW
y_true /= 3600
y_pred /= 3600
# Compute delta, mean and std
delta = np.abs(y_true - y_pred)
mean = delta.mean(axis=0)
std = delta.std(axis=0)
# Plot
# Labels for consumption and temperature
if label.startswith('Q_'):
y_label_unit = 'kW'
else:
y_label_unit = '°C'
# Occupancy
occupancy_idxes = np.where(np.diff(occupancy) != 0)[0]
for idx in range(0, len(occupancy_idxes), 2):
ax.axvspan(occupancy_idxes[idx], occupancy_idxes[idx+1], facecolor='green', alpha=.15)
# Std
ax.fill_between(np.arange(mean.shape[0]), (mean - std), (mean + std), alpha=.4, label='std')
# Mean
ax.plot(mean, label='mean')
# Title and labels
ax.set_title(label)
ax.set_xlabel('time', fontsize=16)
ax.set_ylabel(y_label_unit, fontsize=16)
ax.legend()
plt.savefig('error_mean_std')