Chunk - 2019 December 20¶
[1]:
import numpy as np
from matplotlib import pyplot as plt
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from tqdm import tqdm
import seaborn as sns
from src.dataset import OzeDataset
from src.Transformer import Transformer
from src.utils import visual_sample
[2]:
# Training parameters
DATASET_PATH = 'datasets/dataset_large.npz'
BATCH_SIZE = 4
NUM_WORKERS = 4
LR = 1e-4
EPOCHS = 20
TIME_CHUNK = True
# Testing parameters
TEST_DATASET_PATH = 'datasets/dataset_test.npz'
TEST_MODEL_PATH = 'models/model_00251.pth'
# Model parameters
K = 672 # Time window length
d_model = 48 # Lattent dim
q = 8 # Query size
v = 8 # Value size
h = 4 # Number of heads
N = 4 # Number of encoder and decoder to stack
pe = None # Positional encoding
d_input = 37 # From dataset
d_output = 8 # From dataset
# Config
sns.set()
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(f"Using device {device}")
Using device cuda:0
Training¶
Load dataset¶
[3]:
dataloader = DataLoader(OzeDataset(DATASET_PATH),
batch_size=BATCH_SIZE,
shuffle=True,
num_workers=NUM_WORKERS
)
Load network¶
[4]:
# Load transformer with Adam optimizer and MSE loss function
net = Transformer(d_input, d_model, d_output, q, v, h, K, N, TIME_CHUNK, pe).to(device)
optimizer = optim.Adam(net.parameters(), lr=LR)
loss_function = nn.MSELoss()
Train¶
[5]:
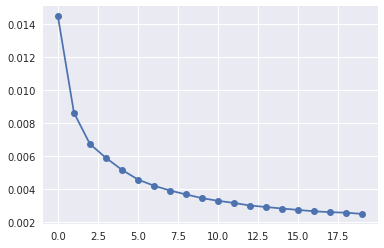
# Prepare loss history
hist_loss = np.zeros(EPOCHS)
for idx_epoch in range(EPOCHS):
running_loss = 0
with tqdm(total=len(dataloader.dataset), desc=f"[Epoch {idx_epoch+1:3d}/{EPOCHS}]") as pbar:
for idx_batch, (x, y) in enumerate(dataloader):
optimizer.zero_grad()
# Propagate input
netout = net(x.to(device))
# Comupte loss
loss = loss_function(netout, y.to(device))
# Backpropage loss
loss.backward()
# Update weights
optimizer.step()
running_loss += loss.item()
pbar.set_postfix({'loss': running_loss/(idx_batch+1)})
pbar.update(x.shape[0])
hist_loss[idx_epoch] = running_loss/len(dataloader)
plt.plot(hist_loss, 'o-')
print(f"Loss: {float(hist_loss[-1]):5f}")
str_loss = str(hist_loss[-1]).split('.')[-1][:5]
torch.save(net, f"models/model_{str_loss}.pth")
[Epoch 1/20]: 100%|██████████| 7500/7500 [03:07<00:00, 39.91it/s, loss=0.0145]
[Epoch 2/20]: 100%|██████████| 7500/7500 [03:09<00:00, 39.63it/s, loss=0.00864]
[Epoch 3/20]: 100%|██████████| 7500/7500 [03:07<00:00, 39.94it/s, loss=0.00674]
[Epoch 4/20]: 100%|██████████| 7500/7500 [03:07<00:00, 39.96it/s, loss=0.0059]
[Epoch 5/20]: 100%|██████████| 7500/7500 [03:08<00:00, 39.79it/s, loss=0.00518]
[Epoch 6/20]: 100%|██████████| 7500/7500 [03:08<00:00, 39.88it/s, loss=0.00459]
[Epoch 7/20]: 100%|██████████| 7500/7500 [03:08<00:00, 39.88it/s, loss=0.00422]
[Epoch 8/20]: 100%|██████████| 7500/7500 [03:08<00:00, 39.85it/s, loss=0.00393]
[Epoch 9/20]: 100%|██████████| 7500/7500 [03:08<00:00, 39.89it/s, loss=0.00369]
[Epoch 10/20]: 100%|██████████| 7500/7500 [03:07<00:00, 39.95it/s, loss=0.00347]
[Epoch 11/20]: 100%|██████████| 7500/7500 [03:08<00:00, 39.69it/s, loss=0.00331]
[Epoch 12/20]: 100%|██████████| 7500/7500 [03:08<00:00, 39.89it/s, loss=0.00318]
[Epoch 13/20]: 100%|██████████| 7500/7500 [03:07<00:00, 39.93it/s, loss=0.00302]
[Epoch 14/20]: 100%|██████████| 7500/7500 [03:08<00:00, 39.72it/s, loss=0.00293]
[Epoch 15/20]: 100%|██████████| 7500/7500 [03:08<00:00, 39.89it/s, loss=0.00284]
[Epoch 16/20]: 100%|██████████| 7500/7500 [03:07<00:00, 39.91it/s, loss=0.00276]
[Epoch 17/20]: 100%|██████████| 7500/7500 [03:09<00:00, 39.67it/s, loss=0.00267]
[Epoch 18/20]: 100%|██████████| 7500/7500 [03:09<00:00, 39.61it/s, loss=0.00262]
[Epoch 19/20]: 100%|██████████| 7500/7500 [03:08<00:00, 39.79it/s, loss=0.00259]
[Epoch 20/20]: 100%|██████████| 7500/7500 [03:09<00:00, 39.62it/s, loss=0.00251]
Loss: 0.002514
Validation¶
Load dataset and network¶
[3]:
datatestloader = DataLoader(OzeDataset(TEST_DATASET_PATH),
batch_size=BATCH_SIZE,
shuffle=False,
num_workers=NUM_WORKERS
)
net = torch.load(TEST_MODEL_PATH, map_location=device)
Plot results on a sample¶
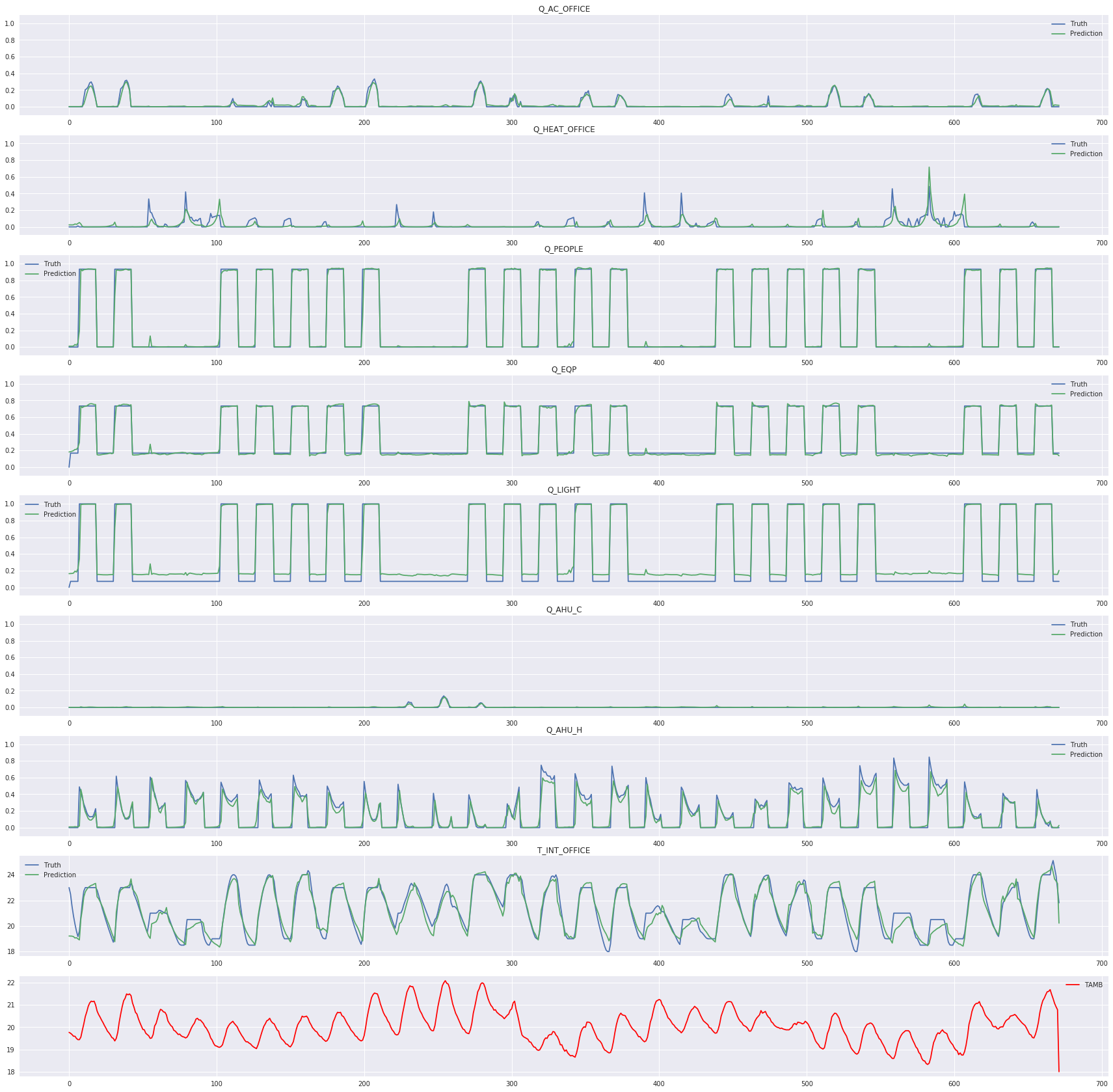
[4]:
visual_sample(datatestloader, net, device)
plt.savefig("fig.jpg")
Plot encoding attention map¶
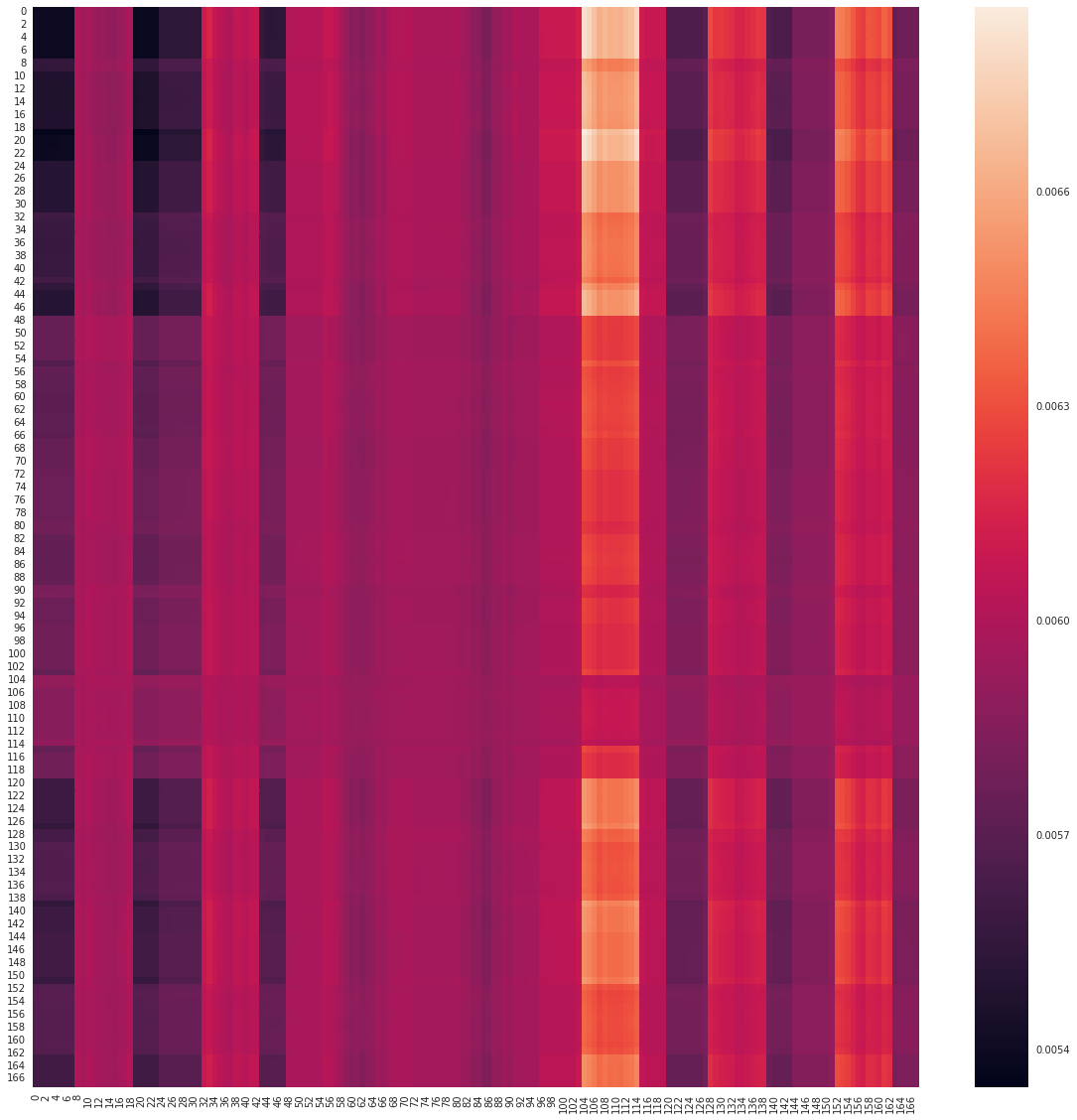
[5]:
# Select first encoding layer
encoder = net.layers_encoding[0]
# Get the first attention map
attn_map = encoder.attention_map[0].cpu()
# Plot
plt.figure(figsize=(20, 20))
sns.heatmap(attn_map)
plt.savefig("attention_map.jpg")
Evaluate on the test dataset¶
[6]:
predictions = np.empty(shape=(len(datatestloader.dataset), K, 8))
idx_prediction = 0
with torch.no_grad():
for x, y in tqdm(datatestloader, total=len(datatestloader)):
netout = net(x.to(device)).cpu().numpy()
predictions[idx_prediction:idx_prediction+x.shape[0]] = netout
idx_prediction += x.shape[0]
100%|██████████| 125/125 [00:05<00:00, 24.52it/s]
[7]:
fig, axes = plt.subplots(8, 1)
fig.set_figwidth(20)
fig.set_figheight(40)
plt.subplots_adjust(bottom=0.05)
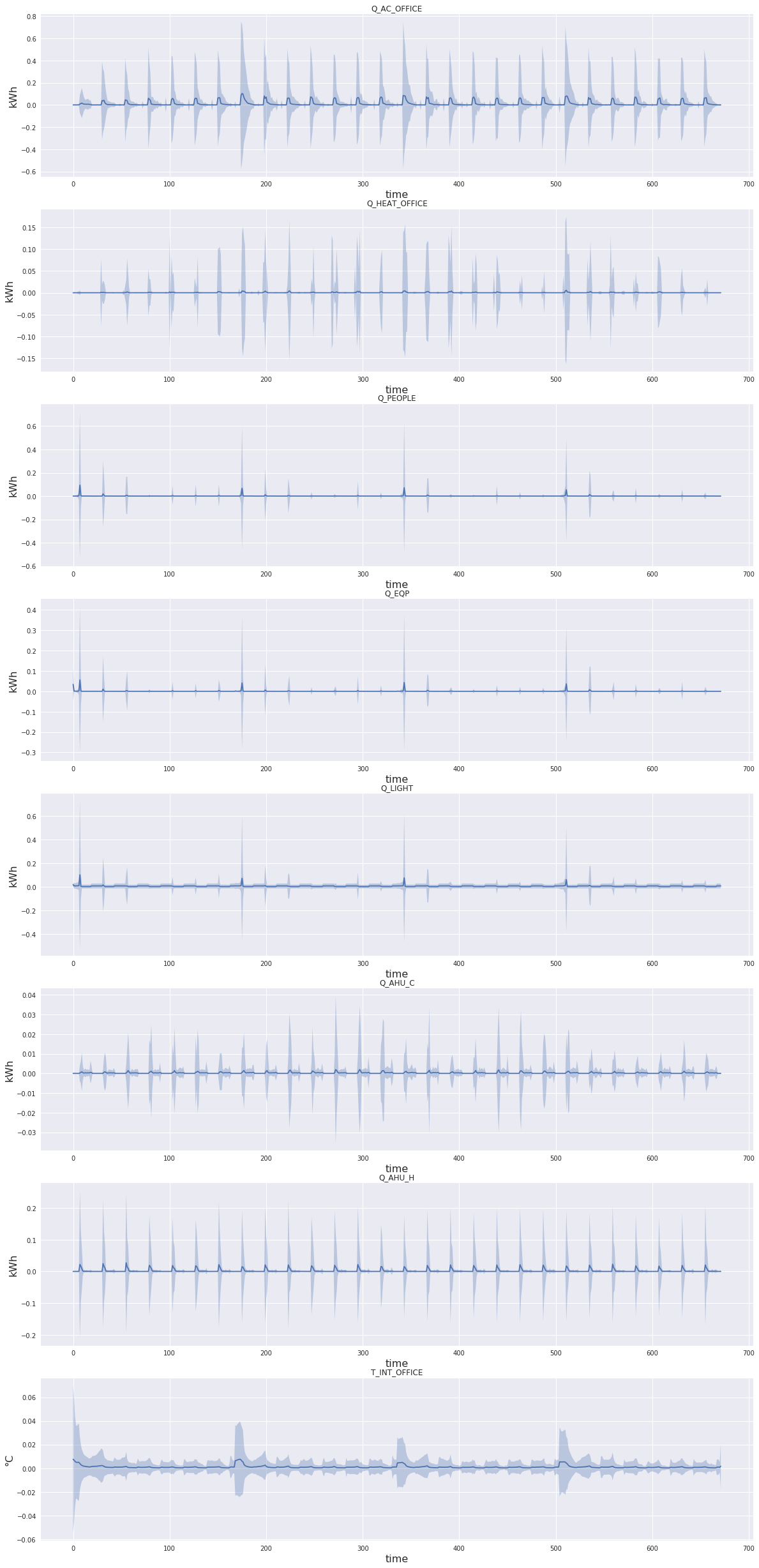
delta = np.square(predictions - datatestloader.dataset._y.numpy())
for idx_label, (label, ax) in enumerate(zip(datatestloader.dataset.labels['X'], axes)):
input_data = delta[..., idx_label]
# For consumption
if label.startswith('Q_'):
y_label_unit = 'kWh'
else:
y_label_unit = '°C'
mean = input_data.mean(axis=0)
std = input_data.std(axis=0)
ax.fill_between(np.arange(K), (mean - 3 * std), (mean + 3 * std), alpha=.3)
ax.plot(mean)
ax.set_title(label)
ax.set_xlabel('time', fontsize=16)
ax.set_ylabel(y_label_unit, fontsize=16)
plt.savefig('error_mean_std.jpg')